Summary: In the rapidly evolving field of generative AI, a groundbreaking paper titled “Fast Text-to-Audio Generation with Adversarial Post-Training” is making waves. Authored by researchers from UC San Diego, Stability AI, and ARM, this study addresses the significant challenge of latency in converting text descriptions into audio. Traditionally, users have faced frustrating delays, waiting seconds or even minutes for audio generation, which hampers real-time and creative applications. The paper introduces a novel approach called Adversarial Relativistic Contrastive (ARC), which aims to enhance speed without compromising the quality or diversity of the generated audio. By prioritizing these elements, ARC paves the way for new possibilities in sound design, potentially transforming how we create and interact with audio. As these tools advance, they promise to open up innovative avenues for interactive audio experiences. For those interested in exploring this cutting-edge technology, the researchers have made their code and a demo site available, offering a glimpse into the future of audio tech.
“`html
In the rapidly evolving field of generative AI, a groundbreaking paper titled “Fast Text-to-Audio Generation with Adversarial Post-Training” is making waves. Authored by researchers from UC San Diego, Stability AI, and ARM, this study addresses the significant challenge of latency in converting text descriptions into audio. Traditionally, users have faced frustrating delays, waiting seconds or even minutes for audio generation, which hampers real-time and creative applications. The paper introduces a novel approach called Adversarial Relativistic Contrastive (ARC), which aims to enhance speed without compromising the quality or diversity of the generated audio.
Understanding the ARC Technique
The ARC methodology is designed to revolutionize text-to-audio generation by focusing on speed and efficiency. The core idea is to use adversarial loss to push the generator model to create more realistic audio. This approach aims to reduce the number of generation steps needed, thereby accelerating the process.
- Relativistic Adversarial Setup: This part of ARC compares real and generated audio samples linked by the same text prompt. The discriminator’s task is to determine which audio is more realistic, making the generator’s goal to produce indistinguishably real audio.
- Contrastive Objective for Discriminator: This encourages the model to understand the relationship between audio and text by comparing correct and shuffled prompt pairs, enhancing prompt adherence without relying on Classifier-Free Guidance (CFG).
- Ping Pong Sampling: An innovative generation technique that iteratively refines audio by alternating between denoising and reintroducing controlled noise, ensuring high-quality audio output with fewer steps.
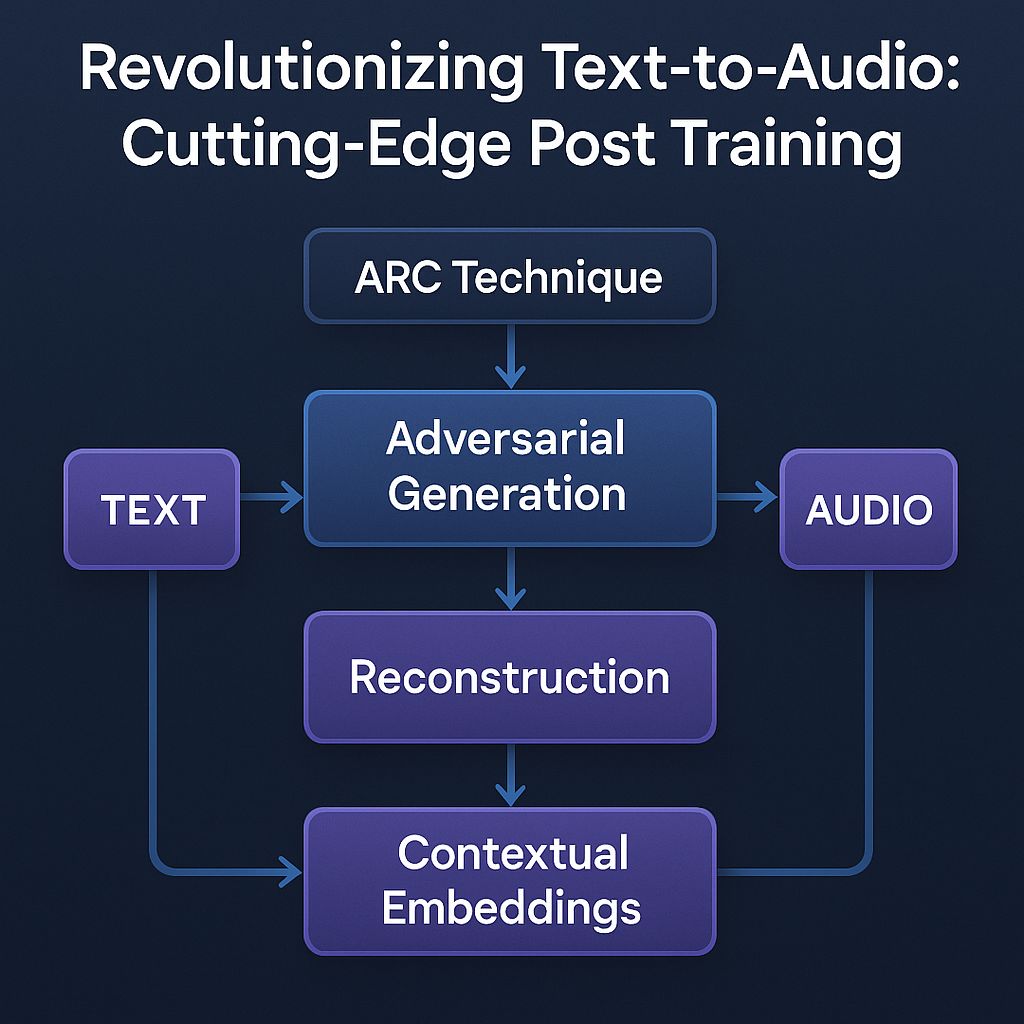
By employing these strategies, ARC not only enhances the speed but also maintains the diversity and quality of audio outputs, making it a promising tool for real-time applications.
Implications for Real-Time Applications
The implications of ARC’s advancements are vast, particularly for industries relying on real-time audio feedback. Here’s how ARC can transform various sectors:
- Gaming: Enabling real-time generation of dynamic sound effects and personalized soundscapes, enhancing player immersion without the need for extensive pre-recorded libraries.
- Virtual Assistants: Providing more natural and contextually appropriate audio responses quickly, improving user interactions.
- Interactive Exhibits: Offering immediate audio responses to user inputs in museums and art installations, creating engaging experiences.
“Reducing latency from many seconds down to milliseconds or just a few seconds completely changes the game for applications needing immediate audio feedback.” – AI Researcher

With these capabilities, ARC opens up new possibilities for interactive audio experiences that were previously impossible due to latency limitations.
Future Prospects and Challenges
While ARC presents remarkable advancements, it also comes with its own set of challenges that need addressing for widespread adoption:
- Resource Usage: Despite optimizations, the models remain large, posing integration challenges within resource-constrained environments like game engines.
- Further Optimization: Continued efforts are necessary to reduce model size and increase efficiency without compromising audio quality.

Nonetheless, the potential applications of ARC are vast, spanning from enhancing gaming experiences to improving virtual assistant interactions. As researchers continue to refine this technology, it promises to redefine how we create and interact with audio.
For those interested in exploring this cutting-edge technology, the researchers have made their code and a demo site available, offering a glimpse into the future of audio tech. Whether you’re a developer, sound designer, or just an AI enthusiast, ARC offers a fascinating look at the future of audio generation.
Summary
The ARC approach to text-to-audio generation is a significant breakthrough, offering rapid audio generation without sacrificing quality or diversity. By leveraging adversarial training, ARC paves the way for real-time applications across various industries, from gaming to virtual assistants. As these tools advance, they promise to open up innovative avenues for interactive audio experiences, reshaping the landscape of sound design and AI interactions.
“`
Leave a Reply